Une requête du modèle TCP/IP ?
Internet est un réseau informatique mondial qui est constitué d’un ensemble de réseaux. L’ensemble utilise un même protocole de communication : TCP/IP, (Transmission Control Protocol / Internet Protocol). L’Internet peut encore représenter pour certains d’entre nous un nouveau paradigme. Toute d’une panoplie des actes physiques courants se passent désormais en ligne sur internet. Recevoir ou envoyer du courrier, établir des appels téléphoniques ou vidéo,… sont des œuvres facilitées par les technologies de l’Internet. Il est donc important de savoir ce qui passe en arrière quand vous demandez une ressource sur internet.
Scénario :
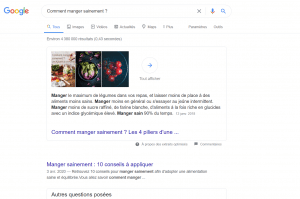
Nathalie veut chercher sur un moteur de recherche « comment manger sainement ? ». Elle utilise un ordinateur connecté à internet et disposant d’un navigateur Google Chrome. Elle ouvre son navigateur et tape sur Google sa question. Nathalie se demande : alors qu’est ce qui se passe quand elle appuie sur la touche entrée de son ordinateur ?
Dans cet article, je vais répondre à la question de Nathalie en expliquant étape par étape ce qui se passe.
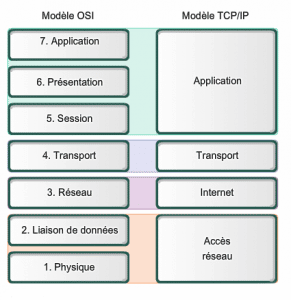
Déjà, comme j’avais mentionné un peu plus haut, l’internet utilise le protocole de communication TCP/IP pour transmettre des données. Alors c’est quoi les modèles TCP/IP ? (Vous pouvez lire mon article sur le modèle TCP/IP vs ISO pour en savoir plus)
TCP/IP
La suite TCP/IP, aussi appelée la suite des protocoles Internet est l’ensemble des protocoles utilisés pour le transfert des données sur Internet. Elle est souvent appelée TCP/IP, d’après les noms de ses deux premiers protocoles : TCP (de l’anglais Transmission Control Protocol) et IP (de l’anglais Internet Protocol).
Le modèle TCP/IP est une approche réaliste ou pratique d’un modèle réseau là où le modèle OSI est un modèle idéalisé ou théoricien. En conséquence, c’est le modèle TCP/IP qui est utilisé comme modèle de réseau de référence pour Internet.
Étape 1
Premièrement, quand Nathalie va appuyer sur la touche entrée après avoir saisi sa question sur la barre de recherche de Google. Les premiers protocoles utilisés vont être HTTP ou HTTPS (HTTP + le protocole de chiffrement TLS). HTTP va permettre d’envoyer la question de Nathalie comme une demande (requête) au serveur de Google. En l’occurrence, la requête sera « renvoie-moi les informations HTML demandé ».
Étape 2
Ensuite, d’autres protocoles vont être utilisés comme DNS (la conversion de www.google.com en adresse IP du serveur de Google ou pour trouver le serveur de Google), etc. Le protocole HTTP permet de créer une requête HTTP. Cette requête (ces données) va devoir être transportée à travers les réseaux.
Étape 3
Pour cela, le système va déjà devoir utiliser un protocole de transport comme TCP par exemple. Celui-ci va garantir l’intégrité des données et la transmission entre processus. À ce niveau, dans la couche de transport, les données venant de différents processus sont transformées en segments.
Étape 4
Chaque segment contient la donnée originale à laquelle est accolé un en-tête de transport. Cet en-tête contient les numéros de ports de la source (du PC de Nathalie) et de la destination (Serveur Google) afin que les données puissent être transmises de manière effective.
Étape 5
Ces segments sont ensuite transmis aux protocoles de la couche Internet. Le rôle de cette couche est de choisir la route la plus rapide à travers le réseau pour que les données arrivent à destination (chez Google). Les segments sont alors transformés en paquets. Cette couche se charge également de l’adressage des données en ajoutant un en-tête aux paquets qui contient l’adresse IP de destination (IP de Google) et celle de départ (IP de Nathalie).
Étape 6
Les paquets sont ensuite à nouveau transformés en frames dans la couche d’accès réseau. A ce niveau, on ajoute un en-tête contenant les adresses MAC (Media Access Control), adresses qui permettent d’identifier tout périphérique de manière unique source et de destination.
Étape 7
Enfin, dans cette même couche, les informations sont finalement transformées en bits (0 et 1 qui correspondent au langage des ordinateurs). Et ces bits sont envoyés dans le réseau (les 0 et les 1 sont encodés dans les câbles en utilisant des transmissions électriques ou des impulsions lumineuses dans le cas de la fibre, via le réseau de Nathalie).
Dès que ces bits arrivent à destination (chez Google), leur point d’entrer : le réseau de Google. Les opérations se déroulent ensuite dans le sens inverse : Les bits sont reformés en frames, puis en paquets, en segments et enfin les données de base sont reconstituées.
Cependant il est important de comprendre comment fonctionne une recherche sur Google et comment Google va gérer, répondre à la question de Nathalie ?

Le fonctionnement de Google repose sur le principe d’une gigantesque base de données. Alimentée et constamment mise à jour par des robots. Les robots analysent le web et indexent les pages trouvées. passant d’une page à l’autre en suivant les liens contenus dans chacun des pages.
Pour chaque page trouvé par les rebots, Google ajoute à sa base de données l’adresse de la page, le contenu de la page (titre, texte, descriptions des images etc.). Et les liens allant vers d’autres pages. C’est cette indexation qui nourrit les résultats affichés par le moteur de recherche.
Pour une requête, il existe des milliers de pages web qui contiennent des informations potentiellement pertinentes. Afin de proposer les meilleures d’entre elles en premier, Google utilise des algorithmes pour évaluer leur utilité.
Des paramètres de recherche à la situation géographique, en passant par l’historique de recherches de l’internaute ! Toutes ces informations permettent à Google de proposer les résultats les plus pertinents et les plus utiles à l’instant t.
Avant de présenter les résultats, Google évalue le lien entre toutes les informations pertinentes qu’il a trouvées. Au fur et à mesure des évolutions du web. Google adapte les systèmes de classement afin de renvoyer des résultats de meilleure qualité.